With the ability to interpolate a circumplex model AUME retrieves audio segments evaluated on a scale of valence and arousal. This model suggests all emotions are distributed in a circular space. High levels of valence correspond to pleasant sounds while low valence levels correspond to unpleasant sounds. Further, high levels of arousal correspond to exciting sounds while low levels correspond to calming sounds. Sound designers evoke emotion from a listener by dynamically controlling valence and arousal levels throughout a com-position. We quantify levels of valence and arousal using machine learning for emotion prediction. The emotion prediction models use a subset of extracted features to predict valence and arousal for each segment in an audio file.
try Impress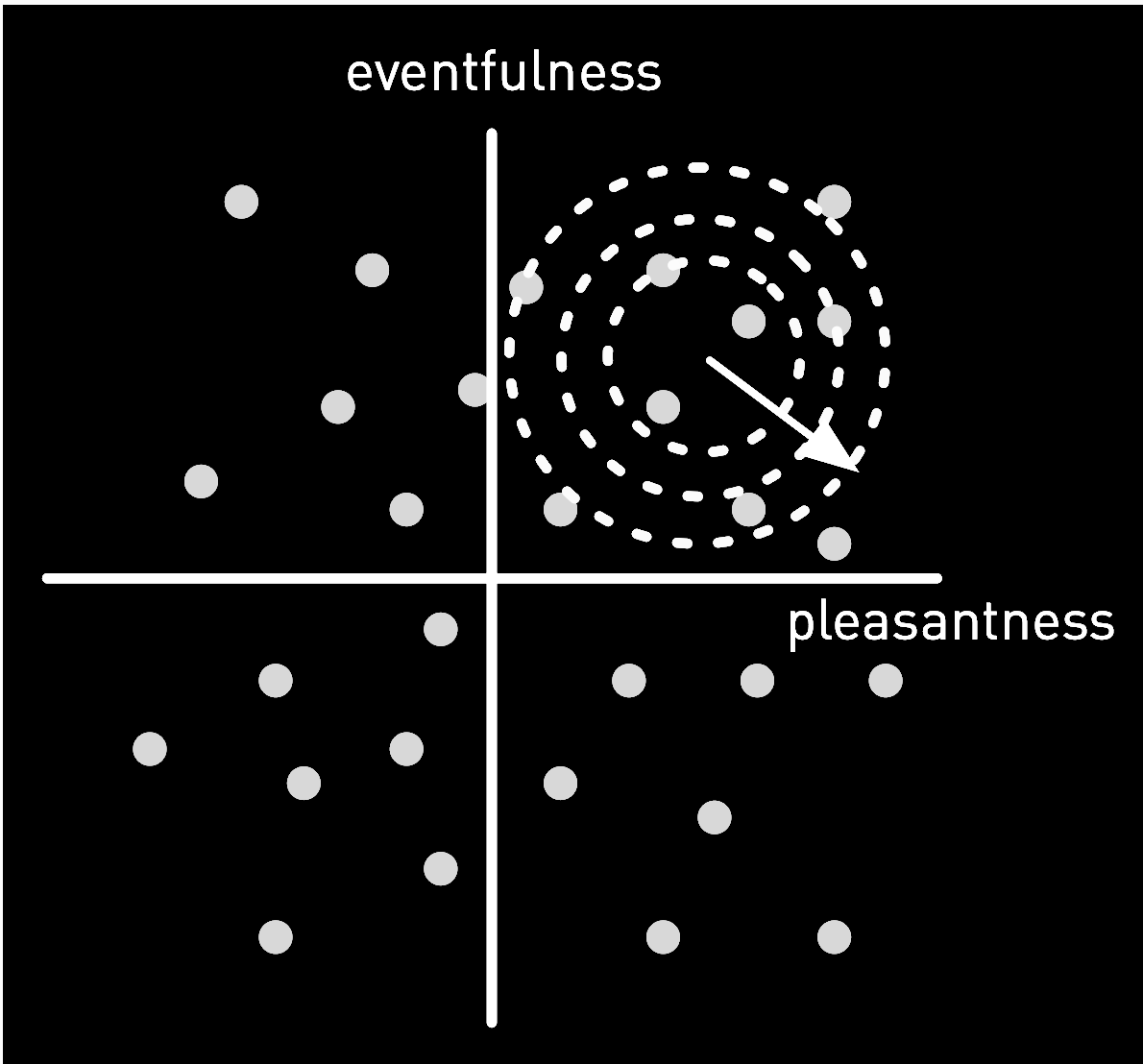
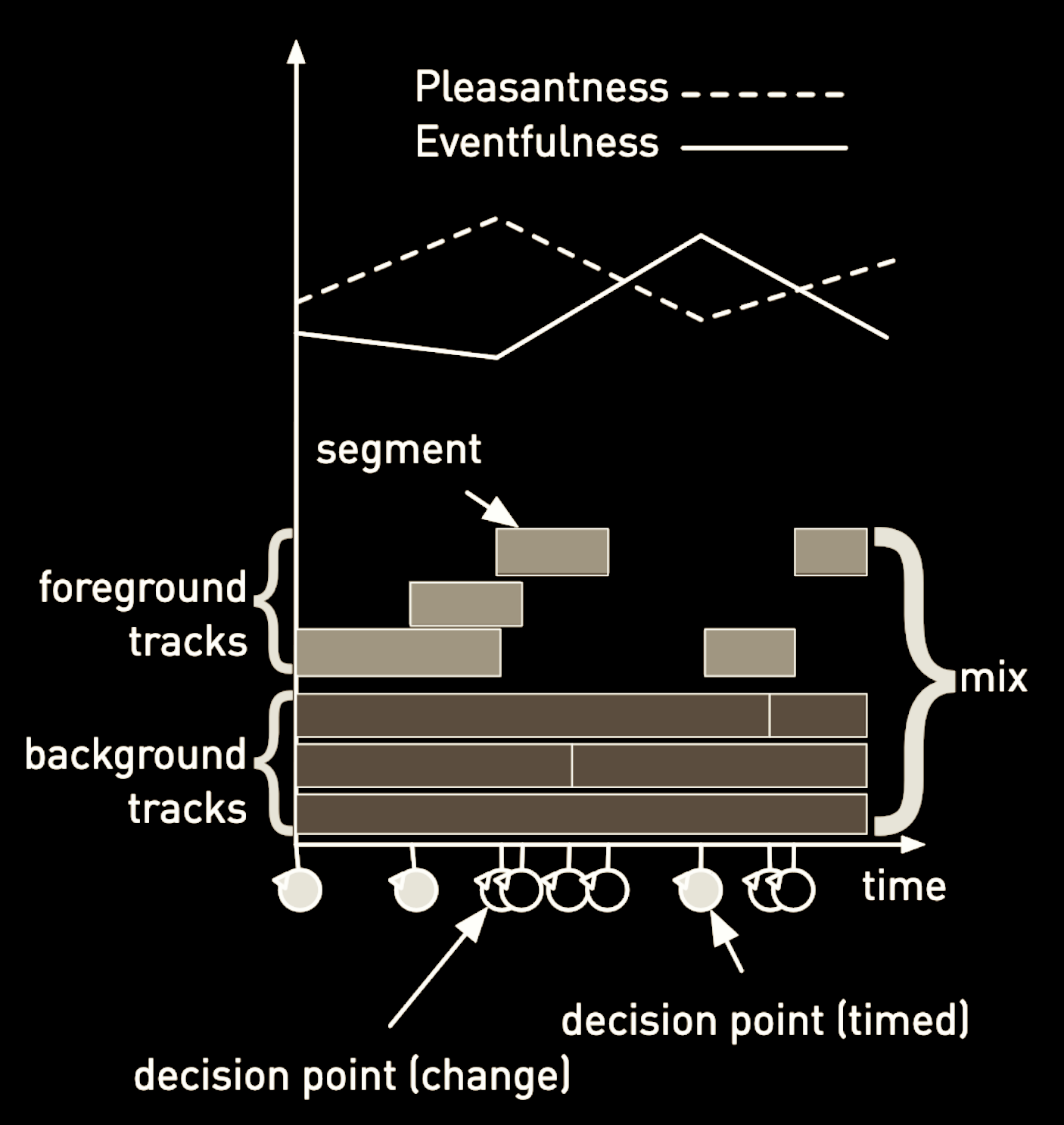
The mixing engine generates a soundscape from a text-based utterance and curves for the movement of valence and arousal over the duration of the soundscape.The engine has access to a database of audio segments indexed by semantic descriptors, valence and arousal values, and background or foreground classification. The engine creates background and foreground tracks for each of the soundscape concepts and assigns sound recording segments to those tracks.
try AuME